Introduction
In the digital age, data is a critical strategic asset, yet it remains highly fragmented, flowing from diverse sources like social media, applications, ERP systems, IoT devices, and cloud services. The challenge lies in collecting, integrating, and transforming this vast, varied data into actionable insights. API-driven data pipelines offer a powerful solution. These automated systems leverage APIs to directly access and process data at its source, enabling near real-time, on-demand data flows. By streamlining integration, they empower organizations to respond swiftly to market changes, optimize operations, and deliver personalized client experiences with up-to-date insights.

What is an API-Driven Data Pipeline?
An API-driven data pipeline is an automated system designed to extract, process, and store data from various sources using Application Programming Interfaces (APIs). Unlike traditional data pipelines that may rely on batch processing or manual data extraction, API-driven pipelines enable seamless, real-time or near real-time data ingestion by directly interfacing with the APIs of external or internal systems. These pipelines are structured to handle diverse data formats, ensure data consistency, and deliver processed data to storage or analytics systems for actionable insights.
API-Driven Data Pipeline Architecture
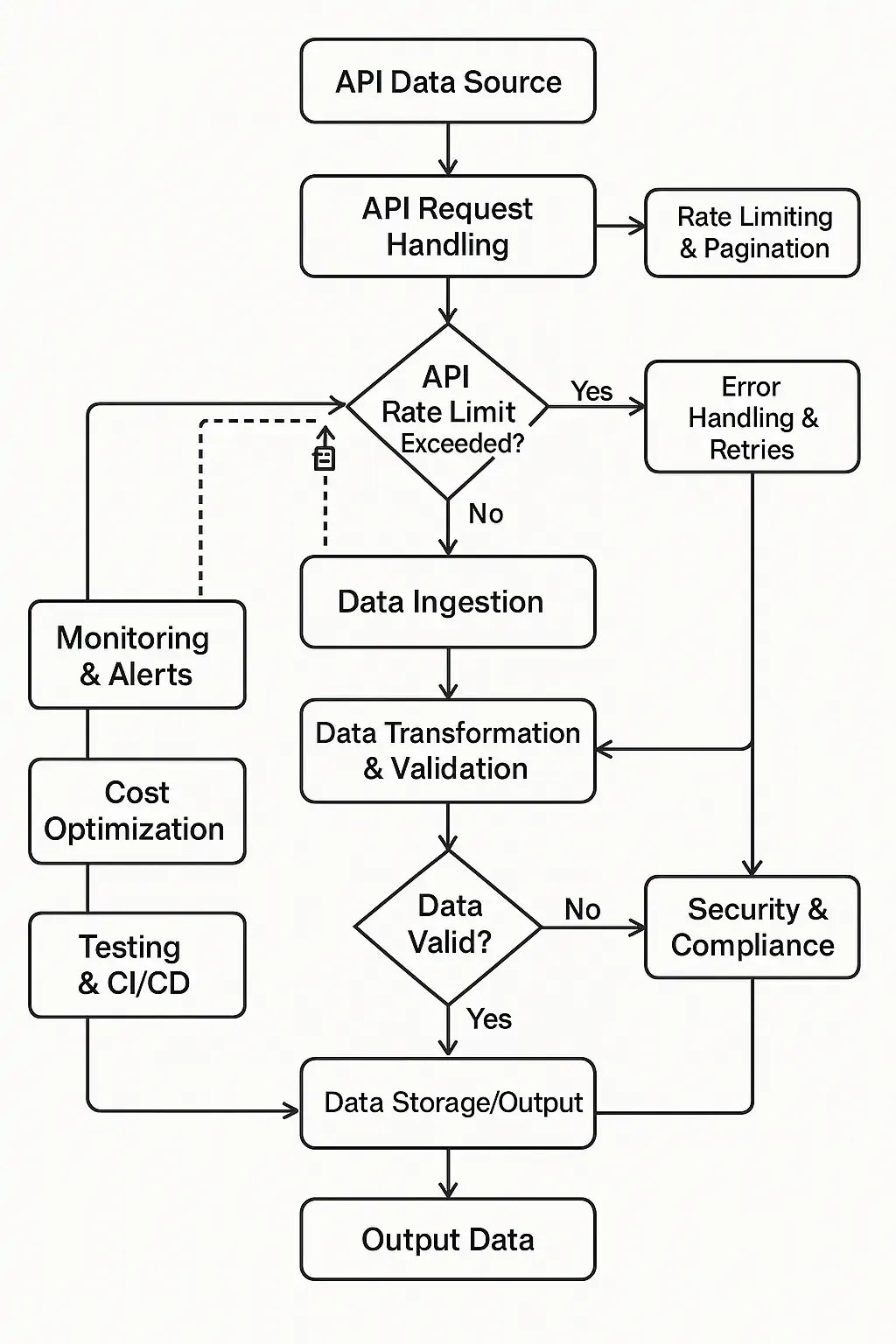
An API-driven data pipeline is a system engineered to automate the ingestion, processing, and storage of data from disparate API sources. To achieve this objective, it is comprised of multiple specialized layers and components, each fulfilling a critical role in ensuring seamless and reliable data flow.
The key components include:
API Data Sources
This is the beginning of any API-driven data pipeline. An API data source is where data originates and is made available via a programmatic interface. These sources can come from:
- Third-Party Services: These are applications or platforms not owned by your organization but that provide valuable data through public or private APIs. Typical examples include the Google Analytics API, Salesforce API, Twitter API, Facebook API, etc.
- Internal Applications with API Endpoints: Within larger organizations, various internal systems, such as Enterprise Resource Planning (ERP), Client Relationship Management (CRM), inventory management applications, or microservices, can also be designed to expose data via internal APIs.
API Connectors / Callers
This component is directly responsible for interacting with API data sources. It functions as a connector or client to dispatch requests to APIs and receive data responses.
API Connector / Caller Implementation:
- You can leverage HTTP client libraries in popular programming languages (e.g., requests in Python, axios in JavaScript, HttpClient in Java/C#) to author custom code that executes API calls.
- Alternatively, specialized API connectors (e.g., readily available connectors within ETL/ELT software for common APIs) can be utilized to minimize programming effort.
Data Storage
This component serves as the persistent storage for data ingested from APIs, making it ready for transformation, analysis, reporting, or other applications. The selection of the storage type hinges on its intended use, data volume, and querying requirements.

Data Transformation
After raw data is ingested from the API, it's typically not immediately ready for analysis. The data transformation layer is responsible for refining and cleansing this data.
Purpose of data transformation:
- Transform raw data (often JSON, XML) from APIs into a more structured, consistent format that aligns with the data model of the target storage.
- Ensure data quality and consistency across the entire data ecosystem.
Commonly used tools for data transformation include Pandas (Python), Apache Spark, and dbt (data build tool).

Tips for Building Effective API-Driven Data Pipeline
To implement a stable and valuable API-driven data pipeline, consider the following points:
Deep API Understanding
- Study API documentation for endpoints, payloads, and limitations (e.g., rate limits, data schemas).
- Test APIs with tools like Postman to handle quirks (e.g., inconsistent responses from social media APIs).
- Map data schemas for each source (e.g., IoT sensor JSON, ERP SQL tables) to ensure compatibility.
Robust Rate Limiting & Pagination
- Use exponential back-off with jitter for rate-limited APIs (e.g., Twitter’s API caps).
- Implement cursor or offset-based pagination for large datasets (e.g., paginated cloud service APIs).
- Checkpoint progress to resume after interruptions, critical for unreliable IoT APIs.
Decoupled & Serverless Architecture
- Use event-driven systems (e.g., AWS EventBridge, Apache Kafka) to decouple ingestion, transformation, and storage.
- Leverage serverless functions (e.g., AWS Lambda, Google Cloud Functions) for scalable processing of diverse data (e.g., social media streams, ERP updates).
- Use message queues (e.g., AWS SQS, RabbitMQ) to handle variable data volumes from IoT devices.
Resilience & Failure Handling
- Implement circuit breakers to prevent pipeline crashes from unstable APIs (e.g., cloud service outages).
- Store failed requests in a dead-letter queue for retry or analysis, crucial for intermittent IoT data.
- Use idempotency keys to avoid duplicates, especially for transactional ERP data.
Data Quality & Integration
- Validate and cleanse data at ingestion (e.g., JSON Schema for social media, Avro for cloud data).
- Standardize formats across sources (e.g., normalize timestamps from IoT and ERP).
- Use tools like Great Expectations to automate quality checks and ensure data integrity.
Comprehensive Monitoring & Observability
- Deploy distributed tracing (e.g., OpenTelemetry) to track data flow across fragmented sources.
- Monitor pipeline health with dashboards (e.g., Grafana) for metrics like latency, error rates, and throughput.
- Set up alerts (e.g., PagerDuty) for critical issues like API downtime or data anomalies.
Cost Optimization
- Cache frequent API calls (e.g., Redis for social media data) to reduce costs and latency.
- Optimize serverless function settings (memory, timeout) for cost-efficient processing.
- Use spot instances or reserved capacity for compute-intensive tasks like IoT data processing.
Security & Compliance
- Secure API keys with secrets management (e.g., AWS Secrets Manager).
- Encrypt data in transit (TLS) and at rest, especially for sensitive ERP or client data.
- Ensure compliance with regulations (e.g., GDPR for social media data, HIPAA for health IoT data) via anonymization and access controls.
Testing & CI/CD
- Build automated tests for each pipeline stage (e.g., unit tests for transformations, integration tests for API calls).
- Use CI/CD pipelines (e.g., GitHub Actions) to deploy updates with minimal downtime.
- Simulate diverse data inputs (e.g., malformed IoT data) to ensure robustness.
Documentation & Collaboration
- Document pipeline architecture, data schemas, and failure recovery processes in tools like Confluence.
- Create source-specific guides (e.g., handling Twitter API rate limits vs. ERP API authentication).
- Foster team collaboration to align on data integration goals and troubleshoot issues.
Benefits of API-Based ETL Pipelines
API-based ETL (Extract, Transform, Load) pipelines offer several advantages over traditional data integration methods, making them a preferred choice for modern data architectures:
- Real-Time Data Access: APIs enable near real-time or on-demand data retrieval, allowing organizations to access up-to-date information without the delays associated with batch processing.
- Scalability and Flexibility: API-driven pipelines can easily adapt to new data sources by integrating additional API endpoints, making them highly scalable.
- Reduced Development Overhead: Pre-built API connectors and libraries (e.g., Python's requests, Postman-generated code) simplify integration, reducing the need for custom scripts or complex middleware.
- Improved Data Quality: APIs often provide structured and validated data, reducing errors during ingestion.
- Cost Efficiency: By leveraging serverless architectures and caching mechanisms, API-based pipelines optimize resource usage, minimizing costs for data processing and API calls, especially for high-frequency or high-volume data sources.
- Enhanced Security: APIs typically include authentication mechanisms (e.g., OAuth, API keys), ensuring secure data access.
- Seamless Integration with Modern Ecosystems: API-driven pipelines integrate effortlessly with cloud platforms (e.g., AWS, Google Cloud) and modern data tools (e.g., Apache Spark, dbt), enabling organizations to build end-to-end data solutions within existing tech stacks.
Use Cases
Client Behavior Analysis
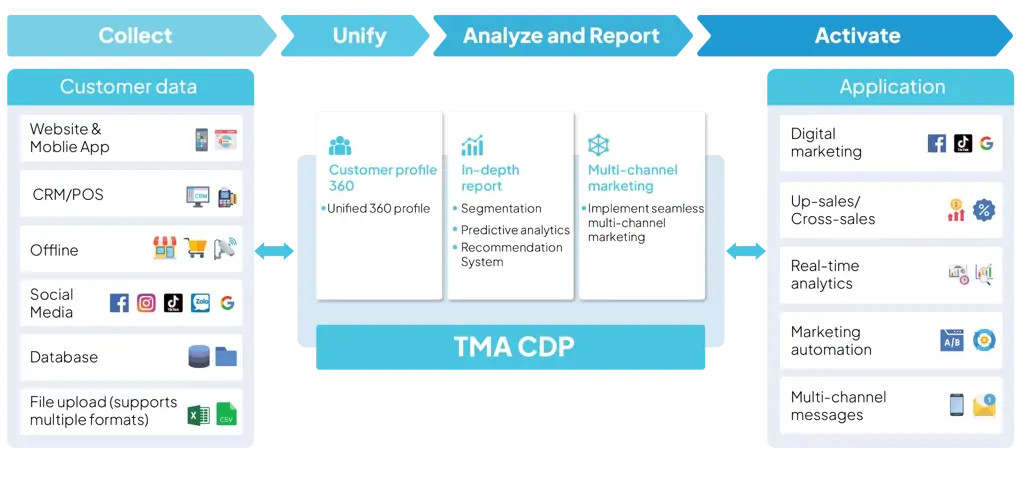
In today's competitive business landscape, client understanding is key to maintaining an edge. TMA's CDP (Centralized Data Platform) project leverages an API-driven data pipeline on AWS to address client data challenges for businesses.
The CDP enables enterprises to:
- Comprehensive Data Collection: Automate data ingestion from CRM platforms (Salesforce, HubSpot), social media (Facebook, Twitter, Instagram), and websites (Google Analytics) to capture interaction history, sentiment, and client journeys.
- Build 360-Degree Client Profiles: Consolidate data from all sources to create a holistic client view, facilitating personalized experiences and optimized marketing.
- Predictive Analytics: Utilize integrated client behavior data to build models for predicting purchase trends, churn probability, and Client Lifetime Value (CLV).
Conclusion
The future of API-driven data pipelines lies in their convergence with AI and ML, enabling smarter, more adaptive, and efficient systems. By automating integration, enhancing data quality, optimizing performance, and ensuring compliance, AI-driven pipelines will empower organizations to harness the full potential of their data. Emerging trends like real-time analytics, low-code platforms, edge computing, federated pipelines, and explainable AI will further accelerate innovation, making these pipelines more accessible, scalable, and impactful. Organizations that embrace these advancements will be well-positioned to turn fragmented data into actionable, real-time insights, driving strategic decisions and competitive advantage.



