Introduction to AI on Edge Devices
AI on edge devices refers to the integration of machine learning models and algorithms directly onto hardware devices located at the periphery of a network. These devices can range from smartphones and wearables to industrial sensors and surveillance cameras. By processing data locally, edge AI eliminates the latency associated with sending information to centralized cloud servers, ensuring immediate responses and enhanced reliability. This is particularly crucial for applications that demand instantaneous decision-making, such as autonomous vehicles, security systems, and industrial automation.
The benefits of edge AI extend beyond speed. It also addresses concerns related to data privacy and bandwidth usage. Since data is processed locally, sensitive information does not need to be transmitted over the internet, reducing the risk of breaches. Additionally, by minimizing the amount of data sent to the cloud, edge AI helps in conserving bandwidth, which is especially valuable in environments with limited connectivity.
Technologies for AI on Edge Devices
Leverage a suite of powerful software development kits (SDKs) to optimize edge device performance across various applications. These SDKs enable high-performance AI and deep learning inference, ensuring that edge devices can handle complex tasks with speed and accuracy. Key technologies driving edge device solutions include: NVIDIA TensorRT SDK, DRP-AI TVM SDK, and Qualcomm Neural Processing SDK for AI (SNPE).
NVIDIA TensorRT SDK
Overview
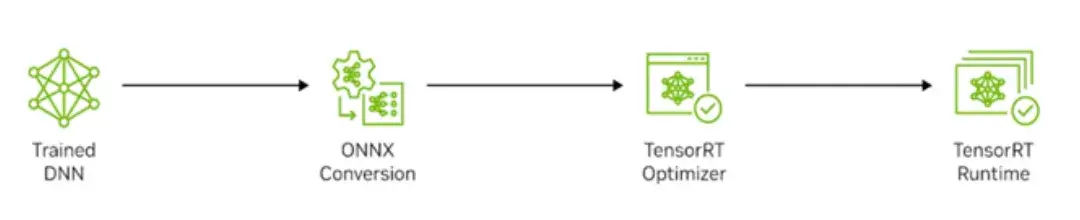
NVIDIA TensorRT is a high-performance deep learning inference library designed to optimize and deploy neural network models on NVIDIA GPUs. Its primary objective is to enable developers to achieve low-latency, high-throughput inference for real-time applications such as autonomous vehicles, robotics, recommendation systems, and AI-driven services. TensorRT transforms trained models from frameworks like TensorFlow, PyTorch, and ONNX into optimized inference engines, maximizing GPU performance while maintaining accuracy.
TensorRT provides APIs via C++ and Python that help to express deep learning models via the Network Definition API or load a pre-defined model via the ONNX parser that allows TensorRT to optimize and run them on an NVIDIA GPU. TensorRT applies graph optimizations, layer fusions, among other optimizations, while also finding the fastest implementation of that mode, leveraging a diverse collection of highly optimized kernels. TensorRT also supplies a runtime that you can use to execute this network on all of NVIDIA’s GPUs from the NVIDIA Turing generation onwards.
Technical Architecture
Built on the NVIDIA CUDA parallel programming model, TensorRT includes libraries that optimize neural network models trained on all major frameworks, calibrate them for lower precision with high accuracy, and deploy them to hyperscale data centers, workstations, laptops, and edge devices. TensorRT optimizes inference using quantization, layer and tensor fusion, and kernel tuning techniques.
NVIDIA TensorRT Model Optimizer provides easy-to-use quantization techniques, including post-training quantization and quantization-aware training to compress your models. FP8, FP4, INT8, INT4, and advanced techniques such as AWQ are supported for your deep learning inference optimization needs. Quantized inference significantly minimizes latency and memory bandwidth, which is required for many real-time services, autonomous, and embedded applications.
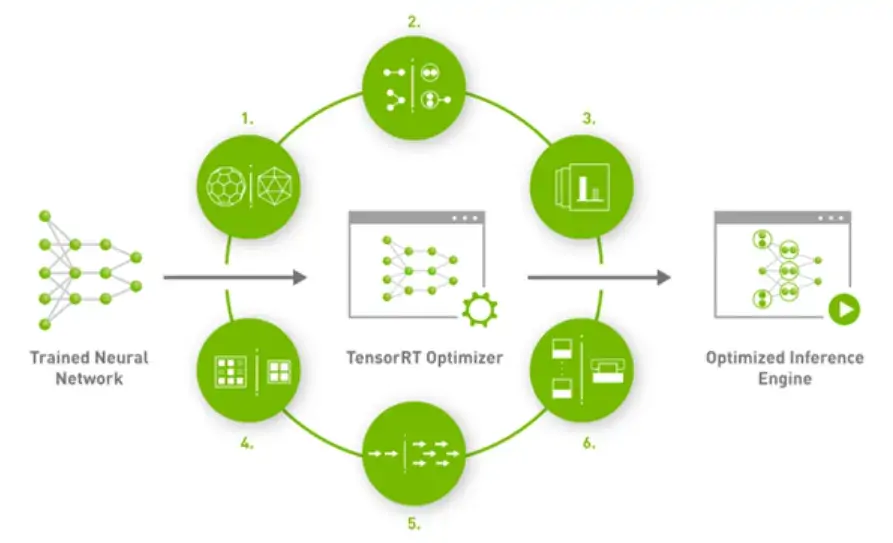
TensorRT operates as a runtime library that integrates with NVIDIA’s CUDA ecosystem to deliver optimized inference. Its architecture consists of the following components:
Weight & Activation Precision Calibration: Maximizes throughput by quantizing models to INT8 while preserving accuracy
Layer & Tensor Fusion: Optimizes the use of GPU memory and bandwidth by fusing nodes in a kernel
Kernel Auto-Tuning: Selects the best data layers and algorithms based on the target GPU platform
Dynamic Tensor Memory: Minimizes memory footprint and reuses memory for tensors efficiently
Multi-Stream Execution: Scalable design to process multiple input streams in parallel
Time Fusion: Optimizes recurrent neural networks over time steps with dynamically generated kernels
TensorRT leverages CUDA and cuDNN for low-level GPU operations and supports deployment across NVIDIA platforms, including data center GPUs (e.g., A100, H100) and edge devices (e.g., Jetson).
Core Concepts
Graph Optimization: TensorRT optimizes neural network graphs by fusing layers (e.g., combining convolution and activation layers) to reduce computation and memory overhead.
Precision Calibration: Supports mixed precision (FP32, FP16, INT8) to balance performance and accuracy, with INT8 requiring calibration datasets for quantization.
Dynamic Tensor Memory: Manages memory dynamically to minimize allocation overhead and support variable input shapes.
Kernel Auto-Tuning: Automatically selects optimal GPU kernels based on the target hardware and model configuration.
Execution Contexts: Enables multiple inference streams or contexts to run concurrently on a single engine, improving throughput.
Key Features and Benefits
High Performance:
Achieves low-latency and high-throughput inference through optimizations like layer fusion and kernel auto-tuning.
Supports multi-GPU and multi-stream execution for scalability.
Precision Flexibility:
Offers FP32, FP16, and INT8 precision modes to optimize for speed or accuracy based on application needs.
Broad Framework Support:
Imports models from TensorFlow, PyTorch, ONNX, and Caffe, ensuring compatibility with popular deep learning ecosystems.
Customizability:
Plugin API enables developers to extend TensorRT with custom layers for specialized operations.
Cross-Platform Deployment:
Runs on NVIDIA GPUs across edge (Jetson) and data center environments, ensuring portability.
Memory Efficiency:
Dynamic memory management reduces GPU memory footprint, critical for resource-constrained devices.
Benefits
Accelerates time-to-market for AI applications by simplifying model optimization and deployment.
Reduces operational costs through efficient GPU utilization.
Enables real-time inference for latency-sensitive applications like autonomous driving and video analytics.
Ecosystem, Community
Ecosystem:
TensorRT integrates with NVIDIA’s broader ecosystem, including CUDA, cuDNN, DeepStream (for video analytics), and Triton Inference Server (for scalable inference).
Supports deployment on NVIDIA platforms like DGX systems, Jetson edge devices, and cloud-based GPUs.
Community:
The NVIDIA Developer Forums provide a platform for TensorRT users to share knowledge, troubleshoot issues, and collaborate.
Extensive sample code and tutorials are available in the TensorRT SDK (/usr/src/tensorrt/samples) and NVIDIA’s GitHub repositories.
DRP-AI TVM SDK
Overview
DRP-AI TVM, developed by Renesas Electronics Corporation, is a specialized tool designed to streamline the deployment of artificial intelligence (AI) models on Renesas’ RZ/V Series Microprocessor Units (MPUs). Its primary objective is to generate runtime executables from trained AI models, enabling seamless integration of AI capabilities into embedded devices such as surveillance cameras, traffic monitoring systems, robots, and drones. By leveraging the open-source Apache TVM framework (Apache TVM), DRP-AI TVM provides a comprehensive solution for AI model conversion and optimization, making it accessible for developers to implement advanced AI functionalities in resource-constrained environments. This tool addresses the challenges of implementing AI in embedded systems, where considerations like hardware performance, cost, and power consumption are critical.
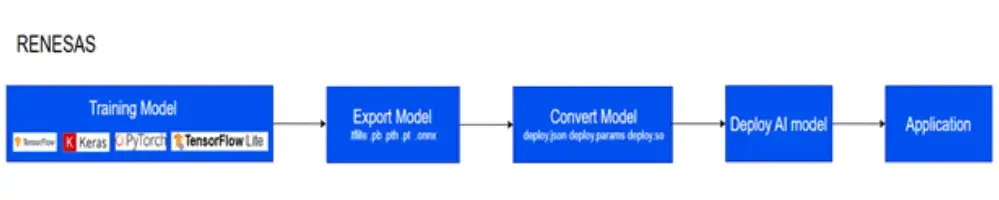
Technical Architecture
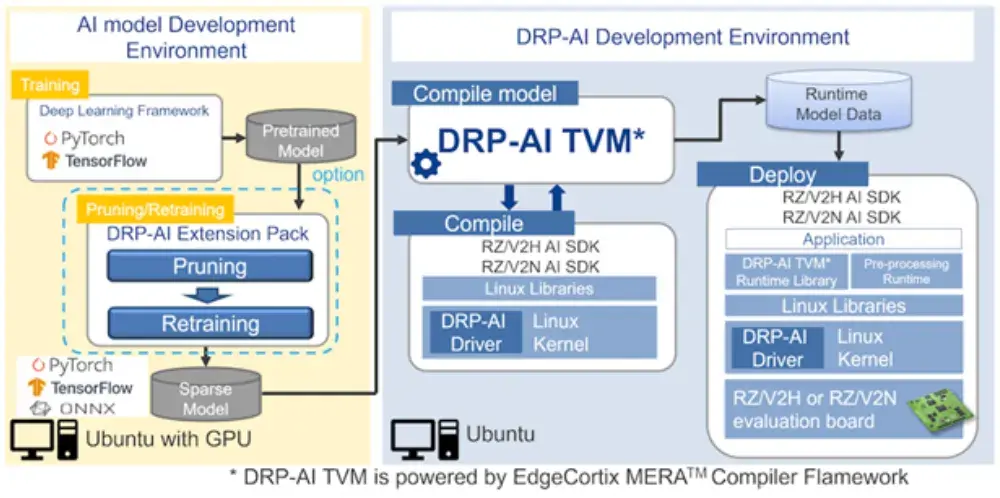
DRP‑AI TVM integrates tightly within both the Renesas toolchain and the broader Apache TVM ecosystem, enabling seamless deployment on RZ/V platforms.
AI Model Development Environment
Training Phase: Models are trained on Ubuntu with a GPU using popular deep learning frameworks as PyTorch, TensorFlow. After training, models can be exported to ONNX format for compatibility.
Pruning / Retraining (Optional): DRP‑AI Extension Pack provides tools for optimizing models:
Pruning: Removes unnecessary weights and connections, making the network smaller and more efficient.
Retraining: Fine-tunes the pruned model to recover any lost accuracy.
DRP‑AI Development Environment
This is where the model is compiled and optimized to prepare it for execution on Renesas hardware:
Model Compilation with DRP‑AI TVM: DRP‑AI TVM takes the Pretrained Model or Sparse Model as input. The model is compiled into an optimized runtime package, targeting RZ/V2H AI SDK, RZ/V2N AI SDK. The compilation process also generates DRP‑AI Driver and Linux Libraries.
Deploy & Inference
This is the phase where the compiled runtime package is deployed on the target device for inference.
Deployment Target: Deployment is performed on RZ/V2H or RZ/V2N evaluation boards.
Runtime Components
DRP‑AI TVM Runtime Library: Executes the optimized AI model.
Pre-processing Runtime: Handles image preprocessing tasks (resizing, normalization, etc.) before feeding data into the AI model.
DRP‑AI Driver: Interfaces with the DRP hardware accelerator.
Linux Kernel & Libraries: Support the runtime environment and applications.
Core Concepts
DRP-AI TVM operates as a Machine Learning Compiler plugin for Apache TVM, enabling the deployment of AI models on Renesas’ DRP-AI accelerator. It supports multiple AI frameworks, including ONNX, PyTorch, and TensorFlow, allowing developers to work with their preferred model formats. The tool converts trained AI models into runtime executables that can be executed on RZ/V Series MPUs. Renesas provides a comprehensive development environment on GitHub (DRP-AI TVM GitHub), which includes tutorials, sample applications, and documentation. A notable tutorial demonstrates deploying an ONNX model on RZ/V series boards (ONNX Model Tutorial). The tool also supports model pruning through the DRP-AI Extension Package, reducing model size and enhancing performance. Additional resources, such as a model list and error list, are available to guide developers through the process.
Key Features and Benefits
DRP-AI TVM offers a robust set of features that enhance its utility for AI deployment in embedded systems:
Multi-Framework Support: It supports ONNX, PyTorch, and TensorFlow, with pruning model generation available for PyTorch and TensorFlow, broadening the range of deployable models.
Model Optimization: Features like INT8 quantization and model pruning reduce model size by up to 90%, improving inference speed while maintaining accuracy. INT8 models require only a few dozen sample images for optimization.
Simplified Deployment Workflow: Provides a clear path from trained model to deployed application on Renesas hardware, reducing development time and complexity.
Scalability: Benefits apply across Renesas' AI-enabled portfolio (RZ/V MPUs, RA MCUs).
Efficiency: Minimizes memory footprint and power consumption – crucial for battery-operated and resource-constrained edge devices.
Advanced Compiler Optimizations: Leverages TVM's strengths like operator fusion, loop optimization, and layout transformation specifically for Renesas hardware.
Power Efficiency: The synergy between the DRP-AI hardware and optimized software ensures high power efficiency, critical for embedded applications.
Ecosystem, Community
DRP-AI TVM is supported by a robust ecosystem maintained by Renesas through the renesas-rz GitHub repository (DRP-AI TVM GitHub). This open-source platform provides access to tutorials, sample codes, demo videos, and documentation, facilitating quick adoption by developers. The integration with Apache TVM connects users to a broader community of AI developers and researchers, fostering collaboration and innovation. Renesas also offers pre-trained models and applications for beginners (Renesas AI Applications), alongside advanced tools like the Bring Your Own Model (BYOM) tutorial for experienced developers.
Qualcomm Neural Processing SDK for AI (SNPE)
Overview
The Qualcomm Neural Processing SDK for AI (formerly SNPE – Snapdragon Neural Processing Engine) is a comprehensive toolkit designed to enable efficient on-device inference of deep neural networks on Qualcomm Snapdragon platforms. It supports heterogeneous execution across CPU, GPU (via OpenCL), and Hexagon DSP, providing optimized pipelines for diverse AI workloads.
Empower developers to seamlessly deploy and accelerate pretrained models (TensorFlow, PyTorch, Caffe, ONNX, TFLite) on mobile and embedded Snapdragon-powered devices, with minimal performance compromise.
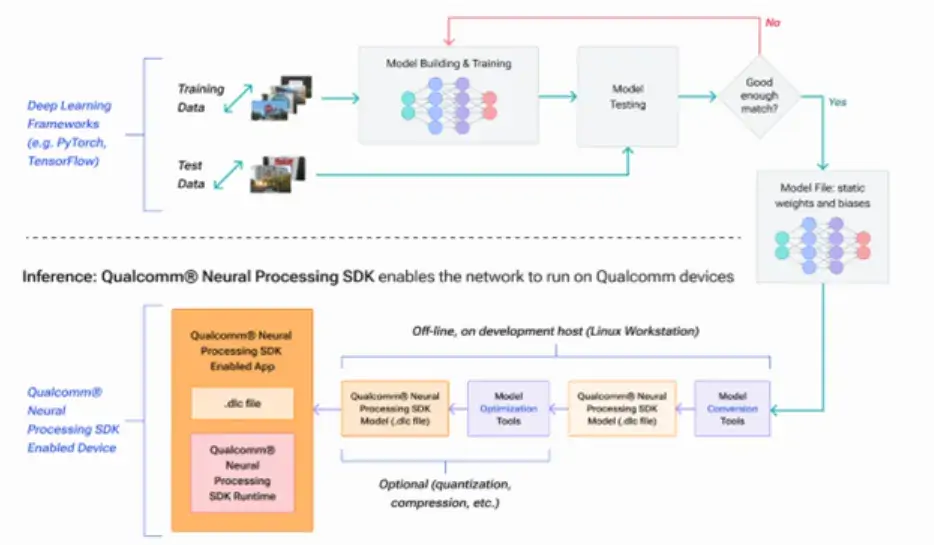
Technical Architecture
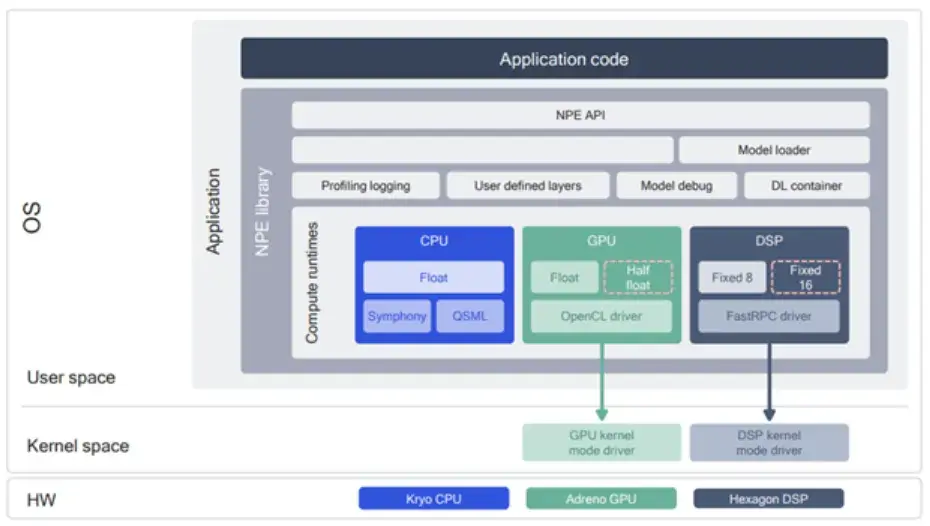
The SDK architecture consists of three main layers:
Application Layer
At the top of the stack is the Application Code, where developers integrate AI functionalities into their apps using the Neural Processing Engine (NPE) API. This layer provides:
Model Loader: For loading trained models into the runtime.
User-Defined Layers: Supports custom neural network layers for advanced use cases.
Model Debugging Tools: To facilitate testing and optimization.
DL Container: For packaging AI models and configurations.
Profiling & Logging: To monitor runtime performance and identify bottlenecks.
NPE Library and Compute Runtimes
The NPE Library acts as the middleware between the application and the hardware. It abstracts the underlying hardware complexity and allows developers to deploy models without deep hardware knowledge. Key runtime components include:
CPU Runtime
Supports floating-point (FP32) operations.
Uses frameworks like Symphony and QCSML for efficient CPU execution.
GPU Runtime
Leverages the Adreno GPU for highly parallel workloads.
Supports floating-point (FP32) and half-precision floating-point (FP16) for faster, energy-efficient inference.
Uses the OpenCL driver for GPU acceleration.
DSP Runtime
Runs on Hexagon DSP for low-power AI tasks.
Supports fixed-point arithmetic (Fixed 8 and Fixed 16) for memory and compute efficiency.
Communicates with hardware via FastRPC driver.
This multi-runtime approach ensures the SDK can allocate workloads optimally depending on the use case, model requirements, and hardware capabilities.
Kernel Space and Hardware Layer
At the lowest level, Kernel Mode Drivers bridge the user space and hardware:
GPU Kernel Mode Driver connects to the Adreno GPU.
DSP Kernel Mode Driver connects to the Hexagon DSP.
Finally, the hardware layer includes:
Kryo CPU
Adreno GPU
Hexagon DSP
This combination enables heterogeneous execution, maximizing Snapdragon’s on-device AI performance
Core Concepts
SNPE is built on several foundational concepts that enable efficient AI model deployment:
Deep Learning Container (DLC) Format: The DLC format is a proprietary representation of neural network models, optimized for execution on Snapdragon processors. It encapsulates the network as a series of connected layers, stored in a compact file format.
Quantization
8-bit Integer (INT8): Default for DSP/NPU.
16-bit Float (FP16): GPU-optimized precision.
Tool: snpe-dlc-quantize for post-training quantization (PTQ).
Runtime Selection: Developers can dynamically target CPU, GPU, or DSP/NPU depending on device capability
User Defined Layers (UDL): SNPE allows developers to prototype custom layers not natively supported, enabling flexibility for specialized use cases.
Buffer Management: Offers flexibility with both internally-managed buffers and zero-copy user-provided buffers via ITensor or UserBuffer interfaces.
Key Features and Benefits
SNPE offers a robust set of features that make it a powerful tool for AI development on Snapdragon devices:
Hardware Acceleration: By leveraging the CPU, GPU, and DSP of Snapdragon processors, SNPE ensures optimized performance tailored to the specific hardware.
Performance Optimization: Tools for quantization, model conversion, and performance analysis enable developers to optimize models for speed and efficiency. For instance, quantization to 8-bit fixed point reduces model size and accelerates inference on DSP.
Multi-Framework Support: SNPE supports model conversion from TensorFlow, Caffe2, ONNX, and other frameworks, making it accessible to developers using various tools.
Performance Analysis Tools: Utilities like snpe-dlc-viewer and snpe_bench.py help developers analyze and optimize network performance, identifying bottlenecks and improving efficiency.
Ecosystem, Community
Qualcomm Developer Network: Official documentation, API references, tutorials, and release notes are accessible on Qualcomm’s developer portal.
QIDK (Qualcomm Innovators Development Kit): Open-source GitHub repo featuring sample applications and showcases using SNPE, QNN, AIMET, etc., with support for Snapdragon 8 Gen2/Gen3 platforms.
Real-World Applications of TMA's AI Solutions on Edge Devices
TMA's AI solutions on edge devices are transforming industries by providing actionable insights and automation through advanced AI capabilities. Below are some of the key applications where TMA's technologies are making a significant impact:
Traffic Counting: Using edge devices equipped with NVIDIA TensorRT, TMA enables accurate, real-time counting of vehicles and pedestrians. This data is invaluable for urban planning, traffic management, and reducing congestion in smart cities. By processing video feeds locally, these devices eliminate the need for constant cloud connectivity, ensuring faster response times and lower operational costs.
People Counting: In retail environments, TMA's AI solutions monitor foot traffic to help businesses understand client behavior. By analyzing this data, retailers can optimize store layouts, improve staffing decisions, and enhance the overall shopping experience. The use of Renesas’s DRP-AI TVM ensures that these devices can operate efficiently even in low-power settings, making them ideal for long-term deployment.
Smoke & Fire Detection: Early detection of smoke and fire is critical for preventing disasters. TMA's AI solutions, powered by NVIDIA TensorRT, can analyze video feeds in real-time to detect signs of fire or smoke, providing instant alerts to emergency responders. This capability is particularly valuable in industrial settings, where rapid response can save lives and prevent costly damage.
Helmet Detection: Safety compliance is a major concern in industries like construction and transportation. TMA's solutions use AI to detect whether individuals are wearing helmets, ensuring adherence to safety protocols. By leveraging Qualcomm SNPE, these devices can perform this task with high accuracy, even in challenging environments.
Intrusion Detection: Securing sensitive areas requires constant vigilance. TMA's AI solutions can detect unauthorized access in real-time, alerting security personnel immediately. This is especially useful for protecting critical infrastructure, such as power plants or data centers, where breaches can have severe consequences.
Weapon Detection: In public spaces like schools, airports, and stadiums, TMA's AI solutions enhance security by detecting weapons through video analysis. Powered by NVIDIA TensorRT, these devices can process large volumes of data quickly, ensuring that potential threats are identified before they escalate.
License Plate Recognition: For law enforcement and traffic management, TMA's AI solutions provide fast and accurate license plate recognition. By using optimized AI models, these devices can identify plates in real-time, aiding in tasks like toll collection, parking management, and vehicle tracking.
Face Recognition: In security and access control, face recognition technology on edge devices offers a seamless way to verify identities. TMA's solutions ensure that this process is both secure and efficient, making it suitable for applications ranging from building access to border control.
Conclusion
TMA's AI solutions on edge devices are reshaping industries by delivering real-time, AI-powered insights directly at the source of data. Through the strategic use of NVIDIA TensorRT, DRP-AI TVM, and Qualcomm SNPE, TMA is enabling a new era of efficiency, safety, and security across applications like traffic management, retail analytics, and public safety. As edge computing continues to evolve, TMA remains committed to pushing the boundaries of what's possible, ensuring that businesses and communities can harness the full potential of AI at the edge.
For more information on how TMA is transforming industries with edge device solutions, explore our service page or read our case study on a successful implementation.



